
微软必应安卓版

- 文件大小:56.65MB
- 界面语言:简体中文
- 文件类型:Android
- 授权方式:5G系统之家
- 软件类型:装机软件
- 发布时间:2024-11-11
- 运行环境:5G系统之家
- 下载次数:111
- 软件等级:
- 安全检测: 360安全卫士 360杀毒 电脑管家
系统简介
全文搜索引擎概述
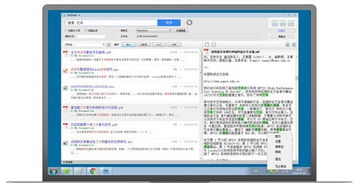
全文搜索引擎是一种能够对文本内容进行索引和搜索的搜索引擎。它通过分析文本内容,建立索引数据库,使得用户可以快速地通过关键词搜索到相关的文档。全文搜索引擎广泛应用于互联网搜索、企业信息检索、内容管理系统等多个领域。
全文搜索引擎的工作原理

全文搜索引擎的工作原理主要包括以下几个步骤:
索引构建:搜索引擎首先对文档进行预处理,包括分词、去除停用词、词干提取等操作,然后将处理后的文本内容建立索引。
查询解析:用户输入查询关键词后,搜索引擎会对关键词进行分词处理,并构建查询表达式。
搜索匹配:搜索引擎根据查询表达式,在索引数据库中查找匹配的文档。
排序和展示:根据文档的相关性对搜索结果进行排序,并将结果展示给用户。
全文搜索引擎的关键技术
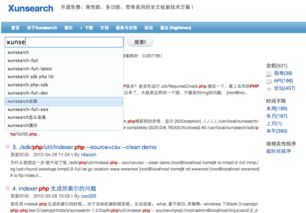
分词技术:分词是将文本切分成有意义的词汇单元的过程。常见的分词方法有正向最大匹配法、逆向最大匹配法、双向最大匹配法等。
停用词过滤:停用词是指对搜索结果影响不大的词汇,如“的”、“是”、“在”等。过滤停用词可以提高搜索的准确性和效率。
词干提取:词干提取是将词汇还原为基本形态的过程,如将“跑步”、“跑步者”、“跑步机”等词汇还原为“跑”。
索引构建:索引构建是将文档内容转换为索引数据的过程,包括倒排索引、正向索引等。
查询解析:查询解析是将用户输入的查询关键词转换为查询表达式的过程。
搜索匹配:搜索匹配是根据查询表达式在索引数据库中查找匹配的文档。
排序和展示:排序和展示是根据文档的相关性对搜索结果进行排序,并将结果展示给用户。
常见的全文搜索引擎
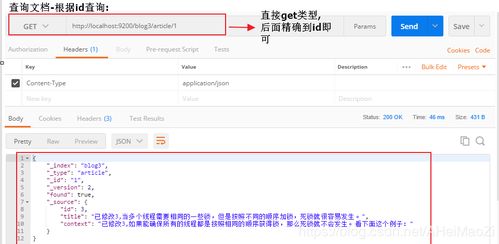
Lucene:由Apache软件基金会开发的开源全文搜索引擎库,是许多搜索引擎的基础。
Solr:基于Lucene构建的开源搜索引擎,具有强大的搜索和分析功能。
Elasticsearch:基于Lucene构建的分布式搜索引擎,适用于处理大规模数据。
Whoosh:Python编写的轻量级全文搜索引擎库。
Wetzel:基于Elasticsearch的搜索引擎,提供RESTful API接口。
全文搜索引擎的应用场景
互联网搜索:如百度、谷歌等搜索引擎。
企业信息检索:如企业内部知识库、产品目录等。
内容管理系统:如WordPress、Drupal等。
社交媒体:如微博、知乎等。
电子商务:如淘宝、京东等。
全文搜索引擎的发展趋势
深度学习:利用深度学习技术提高搜索的准确性和相关性。
个性化搜索:根据用户的历史搜索行为和偏好,提供个性化的搜索结果。
实时搜索:提供实时搜索功能,满足用户对即时信息的需求。
多语言支持:支持多种语言,满足全球用户的需求。
全文搜索引擎作为一种强大的信息检索工具,在各个领域都发挥着重要作用。随着技术的不断发展,全文搜索引擎将更加智能化、个性化,为用户提供更加便捷、高效的搜索体验。



常见问题
- 2025-12-19 hmscore非华为手机安装
- 2025-12-19 小说排行榜
- 2025-12-19 火绒安全软件app下载
- 2025-12-18 远方软件库
装机软件下载排行

其他人正在下载
- 芒物元宇宙商城
- 时尚芭莎手机版
- nice数藏app
- 日淘酱代购安卓版
- 美多萌最新版
- 生动科学免费版
- tokenpocket最新v1.8.7版下载
- 小狐狸官网钱包最新版
- Letstalk官方正版
- whatsapp官方最新版下载
系统教程排行
主题下载
-

幕后沙盒
-

快速摩托车狂飙
-

模拟人类不败作战
-

闲置早餐摊